
Background
There have been numerous attempts to connect text and images.
-
Typical image classifiers are not ‘zero-shot’ they need new labels for any new task.
-
Models like GPT-3 have been shown to be competitive, and often beat, models trained specifically on small datasets, even on those specific datasets, showing the benefits of large-scale self-supervised learning.
-
Some attempts in the past for pre-training has been done (training before labels/supervision), like predicting hashtags for images. However, these classifiers only have a set number of outputs; they are not able to dynamically predict how likely any text is given an image.
-
CLIP model, is basically just the pretrained model, scaled up a lot, (we can predict performance based on scale). The model is designed to learn a representation for an image, and connect this to language. Done on a large scale, the model acts as a classifier, and something that can pair text to language very well. We’ll explore exactly how this is done below.
Approach
The fundamental approach, as outlined before, is taking an image, and predicting the output text.
One part of our model is a representor, which finds the embedding for the image, which uses conv nets and attention.
The other part is a pretrained transformer that understands information from the text (like BERT, it’s an encoder).
Architecture
Fundamentally, the model takes an image, and outputs the log probabilities for different words that we give it. So, we can feed the class labels into a text encoder, and preform classification tasks with our model, or we can just feed in arbitrary text, and our model will say how likely it is given an image.
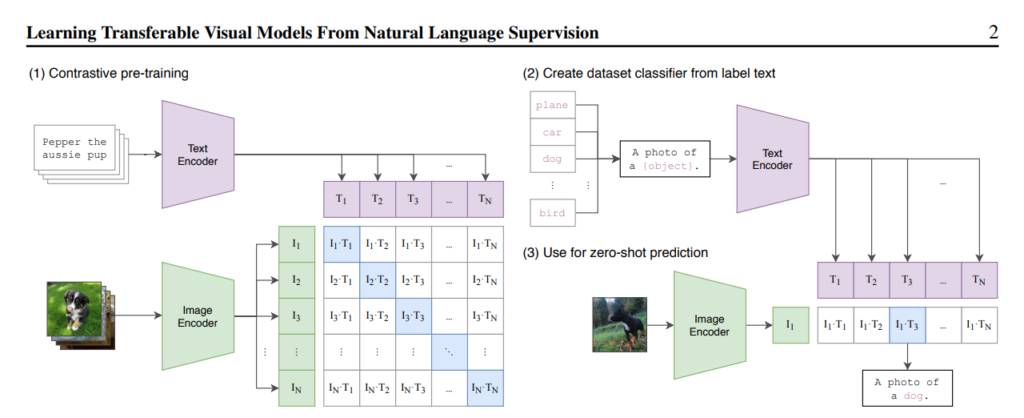
So, we just make the models loss function it’s ability to ‘match’ different encodings from text and images. It also has to learn to make the other encodings low (cross-entropy likelihood). Now we have two encoders that give similar embeddings for similar image-text pairs. We could think of now plugging in arbitrary text, training an image decoder, and generating images for our text! It would also help to have a structured, probabilistic latent space for this task.
Scratch implementation
Now, let’s create a minimalistic scratch-implementation of CLIP for image generation! First we need our encoders for our text and image. Let’s use a simple pre-trained transformer, and a ResNet.
Here is the most important code, which is for the loss function:
# testing clip loss w/ minimal implementation
import torch.nn as nn
import torch.nn.functional as F
# image vectors B, Embd
txt = torch.randn((12,100))
images = torch.randn((12,100))
# normalizing so add to 1
txt = F.normalize(txt)
images = F.normalize(images)
t = 0.01 # learned temperature parameter for sensitivity scaling
# get inner-products
corr_logits = images@txt.T # : dot product of text and images, row=text,col=img
# cross-entropy
labels = torch.arange(corr_logits.shape[0])
# for each row, picking out target label (collumn of row)
criterion = nn.CrossEntropyLoss()
loss = criterion(corr_logits,labels)
print(loss)All we do, is take our two vectors, calculate their similarities (logit probabilities they assign), and model the loss function based on this.
Now, let’s add our encoders and decoders, and make this a real model:
Application to our model
Now, we will use a pre-trained CLIP model for the input to our diffusion-based model. We will use it to train the embeddings for our text that corresponds to the latent vector of the image.